Warehouse Shipment Tracking for Home Chef
Home Chef
Home Chef is a company that delivers pre-packaged ingredients for meals. They were founded in 2013 in Chicago, IL, and have already expanded to selling 2.5 million meals per month to people in 48 states. With this expansion comes a need for automation, so I took on the challenge of tracking what boxes are in shipments that are arriving and departing from their warehouse. This was largely a demonstration of what can be tracked, and I started out by detecting and tracking two types of boxes.
Home Chef Boxes

Ice Pack Boxes

I am not counting the number of boxes, but rather detecting what boxes are in a shipment. However, some shipments have multiple types of boxes stacked together, so I am also testing the feasibility of differentiating between boxes in a shipment.
Camera Setup
I set up a webcam between two truck ports so I could view boxes coming in and leaving the warehouse. By tracking whether boxes enter or exit from the left or right, it is possible to tell which truck is being loaded or unloaded.


The webcam was set to constantly take images. To save storage space and lower computing time, images were only kept if movement was detected. This was done by counting the number of pixels that had their colors change from the previous image. A threshold was made for the amount the color could change, and a threshold for the number of pixels that could change color, before it was considered motion.
Object Recognition with YOLO
As I showed in another project, Convolutional Neural Networks can be used to classify objects in an image. However, an image classifier will look at the entire image and is meant to detect one class. For tracking boxes, there are multiple classes and we need to be able to tell where it is moving within the image. It is possible to scan an image to identify objects, but that is inefficient. Instead I used an object localizer that outputs the classes and bounding boxes for multi-class objects in an image. It is more efficient because it doesn’t scan the image, thus its name You Only Look Once (YOLO).
The YOLO localizer works by having the bounding boxes and prediction probability for classes as part of the output layer of the neural network.

The image is first divided into a grid, and each grid cell predicts multiple bounding boxes. In the above example, the predicted bounding boxes are shown, with higher probabilities shown with bolder boxes. The boxes with probabilities above a threshold are then shown in the final image, and it has successfully identified the dog, bike, and truck.
I created a training image set by using rectLabel to label bounding boxes around objects in images.
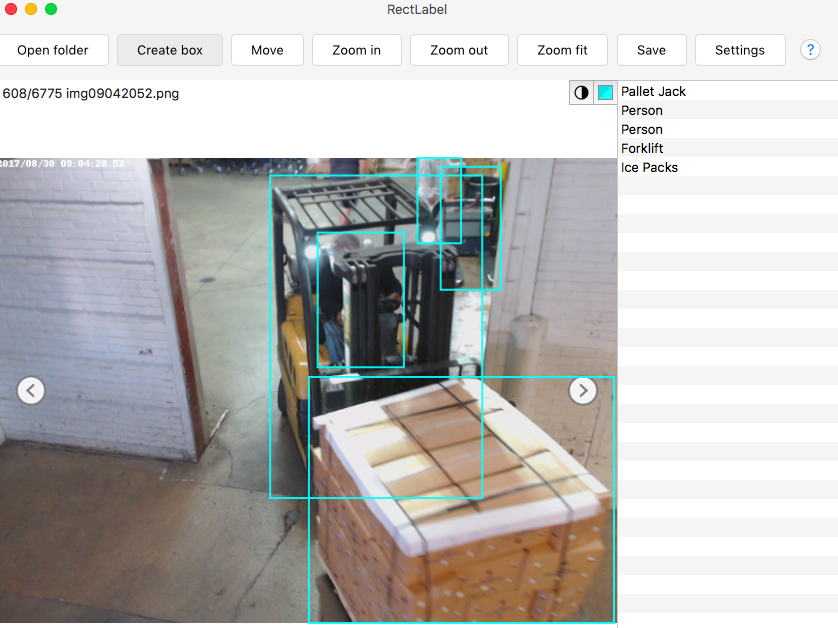
I labeled 750 shipments of Home Chef boxes and 250 shipments of Ice Packs. There were not enough images to train other classes of boxes, so I labeled 415 people, 550 forklifts, and 615 pallet jacks to test the limitations of the object detection.
Performance
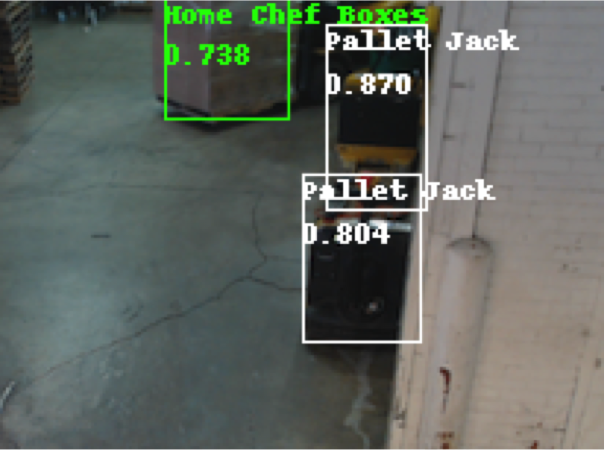
This video above shows the object detection as a shipment arrives. It detects the forklift, pallet jacks, and Home Chef boxes in the background. It detects the incoming Home Chef boxes as soon as the corner comes into view, and the person driving the forklift. It continues to label the forklift, even when it is almost entirely obstructed by the Home Chef boxes and/or wall. This shows it is feasible to use YOLO to detect multiple types of boxes stacked in the same shipment if given enough training images.
The localizer is also capable of detecting Home Chef boxes regardless of the color of wrap used, or even multi-colored wrapping.
 |  |
 |  |
 |  |
It can also distinguish between Home Chef and Ice Pack boxes, even in examples where they are the most similar shape and color.

Supplemental Computer Vision
The YOLO localizer is built on the darknet neural network framework, which is optimized for GPU but slow on a CPU (typically 6 seconds per image on a MacBook). It is possible to optimize YOLO for a CPU, and there are examples available to use (i.e. cpuNet) that are able to do 15 fps for one class with a smaller neural network. However, we may want to scale this to a large number of classes, and run this on a small computer or Raspberry Pi, but still maintain high accuracy and speed. I thus investigated the use of other computer vision algorithms that might be used to supplement YOLO.
Optical Flow
Optical flow can be used to trace the movement of groups of pixels in an image. This in turn be used to observe where there is motion in the image, its direction, and even speed. The image below shows the optical flow as vectors, tracing the motion of the forklift and boxes.
This can be used to detect where there is motion in the image, and which direction it is going. I divided the image into three sections: two foreground areas on each side for the two truck ports, and a section toward the center of the image for motion through the entryway. Logical sequences of motion can thus be used to decide when to use YOLO to detect whether there are boxes associated with the motion. For example, if a forklift with boxes is coming in from the left, the boxes will not be in view to start:

However, if there is no longer motion on the left, but there is upward motion in the center, this is an optimal time to use YOLO to detect whether there are boxes or not.


Logical sequences were created for different possible situations. When exiting, motion is first detected in the center and the boxes are immediately identified, then which port the boxes exit through is determined. Another possible situation is when entering, the forklift turns around in the foreground before exiting. In this case, the boxes are sometimes behind the forklift before there is no more motion at the entry port. So in this case, it worked best to detect the boxes when the forklift and boxes were spanning between the two entry areas.
Object tracking
Once boxes have been identified and bounding boxes are found, their motion can then be traced by an object tracker to verify that they are going into or out of the warehouse. I tested various object tracking algorithms, and found the Kernelized Coefficient Filters (KCF) worked best because it worked well for objects changing size and rotating. I used the bounding box from YOLO as the input for a KCF object tracker to follow the boxes into the warehouse:
This object tracker is also much faster than YOLO, saving processing time.
Records
The information collected can then be saved, including the time, whether it’s an arrival or departure, which port (1 or 2), what type of boxes, and a link to a video file of the event.
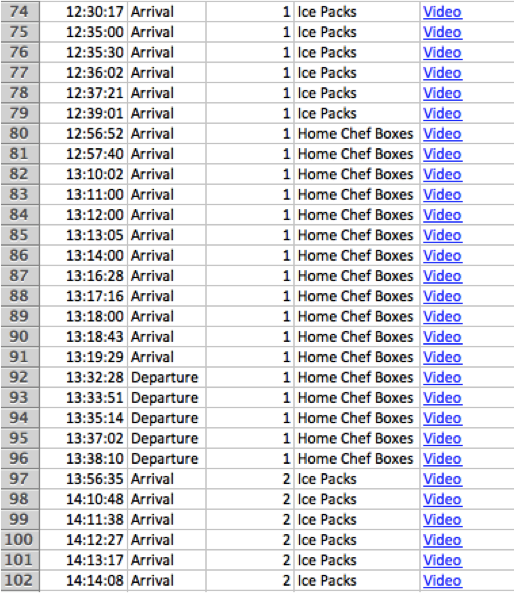
This level of information was not previously possible without object recognition and computer vision.