Identifying Low-Quality and Potentially Fake Amazon Reviews
Amazon Reviews
Amazon.com sells over 372 million products online (as of June 2017) and its online sales are so vast they affect store sales of other companies. But they don’t just affect the amount that is sold by stores, but also what people buy in stores. It’s a common habit of people to check Amazon reviews to see if they want to buy something in another store (or if Amazon is cheaper). For this reason, it’s important to companies that they maintain a postive rating on Amazon, leading to some companies to pay non-consumers to write positive “fake” reviews. As a consumer, I have grown accustomed to reading reviews before making a final purchase decision, so my decisions are possibly being influenced by non-consumers.
Another barrier to making an informed decision is the quality of the reviews. While more popular products will have many reviews that are several paragraphs of thorough discussion, most people are not willing to spend the time to write such lengthy reviews. This often means less popular products could have reviews with less information. While they still have a star rating, it’s hard to know how accurate that rating is without more informative reviews.
In reading about what clues can be used to identify fake reviews, I found may online resources say they are more likely to be generic and uninformative. This brings to mind several questions. Can low-quality reviews be used to potentially find fake reviews? Are products with mostly low-quality reviews more likely to be purchasing fake reviews? Can we identify people who are writing the fake reviews based on their quality?
Here I will be using natural language processing to categorize and analyze Amazon reviews to see if and how low-quality reviews could potentially act as a tracer for fake reviews.
UCSD Dataset
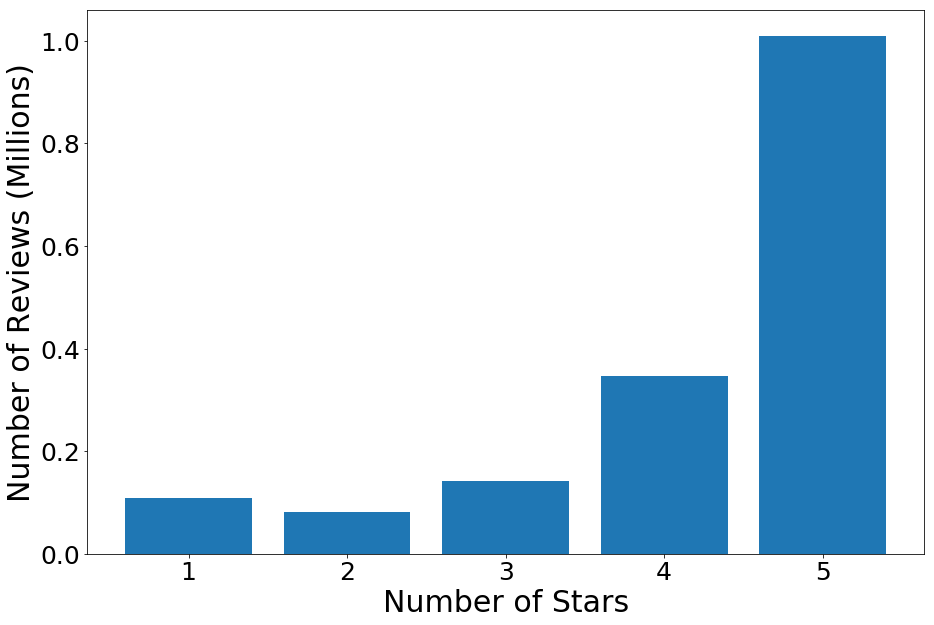
To create a model that can detect low-quality reviews, I obtained an Amazon review dataset on electronic products from UC San Diego. The dataset contains 1,689,188 reviews from 192,403 reviewers across 63,001 products. Most of the reviews are positive, with 60% of the ratings being 5-stars.
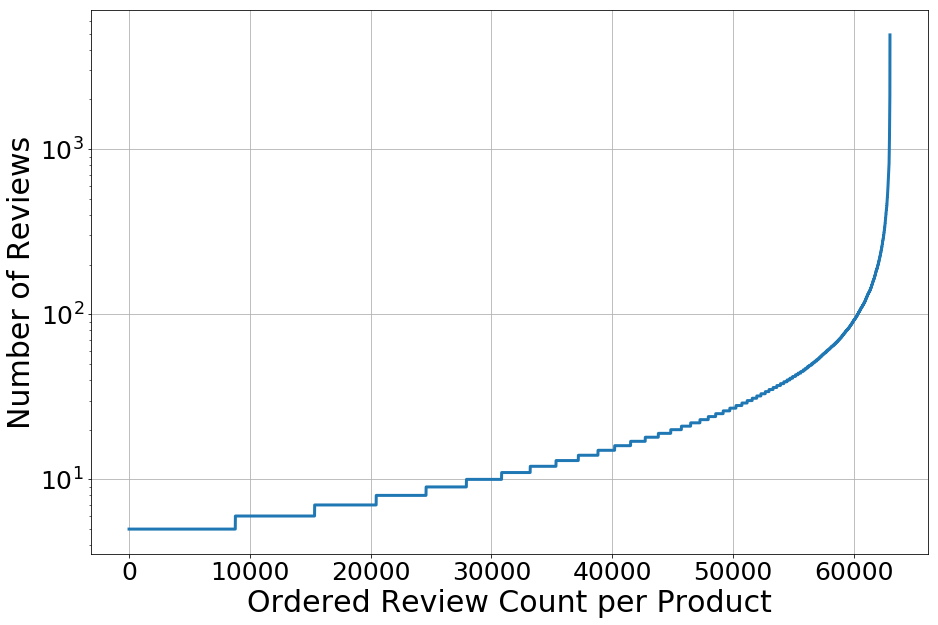
Looking at the number of reviews for each product, 50% of the reviews have at most 10 reviews. The product with the most has 4,915 reviews (the SanDisk Ultra 64GB MicroSDXC Memory Card).
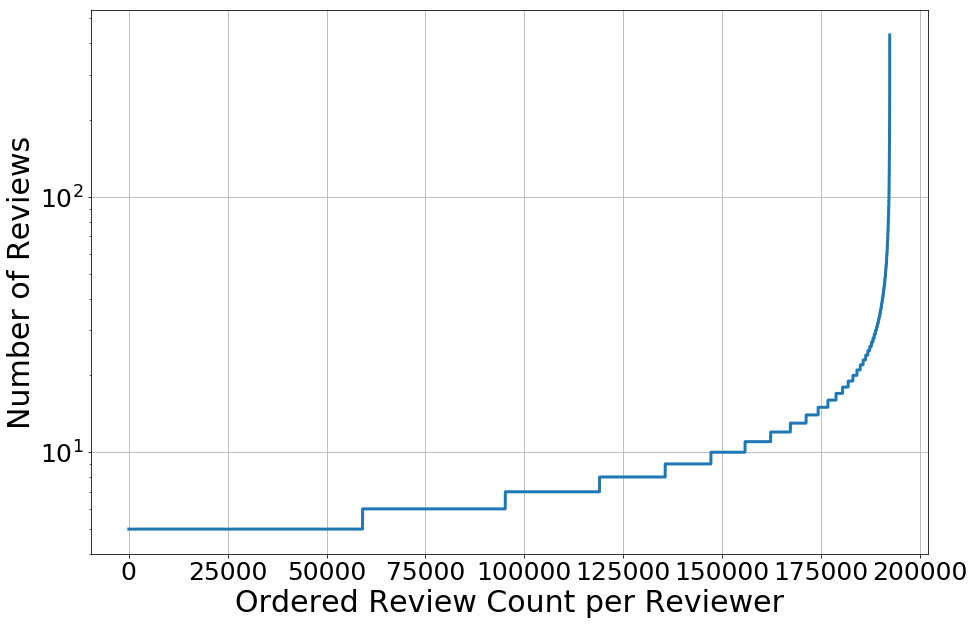
For the number of reviews per reviewer, 50% have at most 6 reviews, and the person with the most wrote 431 reviews.
The Model
For each review, I used TextBlob to do sentiment analysis of the review text. The polarity is a measure of how positive or negative the words in the text are, with -1 being the most negative, +1 being most positive, and 0 being neutral. This package also rates the subjectivity of the text, ranging from 0 being objective to +1 being the most subjective.
I then used a count vectorizer count the number of times words are used in the texts, and removed words from the text that are either too rare (used in less than 2% of the reviews) or too common (used in over 80% of the reviews). I then transformed the count vectors into a term frequency-inverse document frequency (tf-idf) vector. A term frequency is the simply the count of how many times a word is in the review text. The term frequency can be normalized by dividing by the total number of words in the text. The inverse document frequency is a weighting that depends on how frequently a word is found in all the reviews. It follows the relationship log(N/d) where N is the total number of reviews and d is the number of reviews (documents) that have a specific word in it. If a word is more rare, this relationship gets larger, so the weighting on that word gets larger. The tf-idf is a combination of these two frequencies. This means if a word is rare in a specific review, tf-idf gets smaller because of the term frequency - but if that word is rarely found in the other reviews, the tf-idf gets larger because of the inverse document frequency. Likewise, if a word is found a lot in a review, the tf-idf is larger because of the term frequency - but if it’s also found in most all reviews, the tf-idf gets small because of the inverse document frequency. In this way it highlights unique words and reduces the importance of common words.
There are tens of thousands of words used in the reviews, so it is inefficient to fit a model all the words used. Instead, dimensionality reduction can be performed with Singular Value Decomposition (SVD). As I illustrate in a more detailed blog post, the SVD can be used to find latent relationships between features. The principal components are a combination of the words, and we can limit what components are being used by setting eigenvalues to zero. I limited my model to 500 components.
Next, I used K-Means clustering to find clusters of review components. A cluster is a grouping of reviews in the latent feature vector-space, where reviews with similarly weighted features will be near each other. This means a single cluster should actually represent a topic, and the specific topic can be figured out by looking at the words that are most heavily weighted. For example, clusters with the following words were found, leading to the suggested topics:
speaker, bass, sound, volume, portable, audio, high, quality, music... = Speakers
scroll, wheel, logitech, mouse, accessory, thumb… = Computer Mouse
usb, port, power, plugged, device, cable, adapter, switch… = Cables
hard, drive, data, speed, external, usb, files, fast, portable… = Hard Drives
camera, lens, light, image, manual, canon, hand, taking, point… = Cameras
Other topics were more ambiguous. For example, one cluster had words such as:
something, more, than, what, say, expected…
Reading the examples showed phrases commonly used in reviews such as “This is something I…”, “It worked as expected”, and “What more can I say?”. So these types of clusters included less descript reviews that had common phrases. When modeling the data, I separated the reviews into 200 smaller groups (just over 8,000 reviews in each) and fit the model to each of those subsets. These types of common phrase groups were not very predictable in what words were emphasized.
However, one cluster for generic reviews remained consistent between review groups that had the three most important factors being a high star rating, high polarity, high subjectivity, along with words such as perfect, great, love, excellent, product. The reviews from this topic, which I’ll call the low-quality topic cluster, had exactly the qualities listed above that were expected for fake reviews. I used this as the target topic that would be used to find potential fake reviewers and products that may have used fake reviews.
Model Results
Products
I modeled each review in the dataset, and for each product and reviewer, I found what percentage of their reviews were in the low-quality topic. The percentage is plotted here vs. the number of reviews written for each product in the dataset:
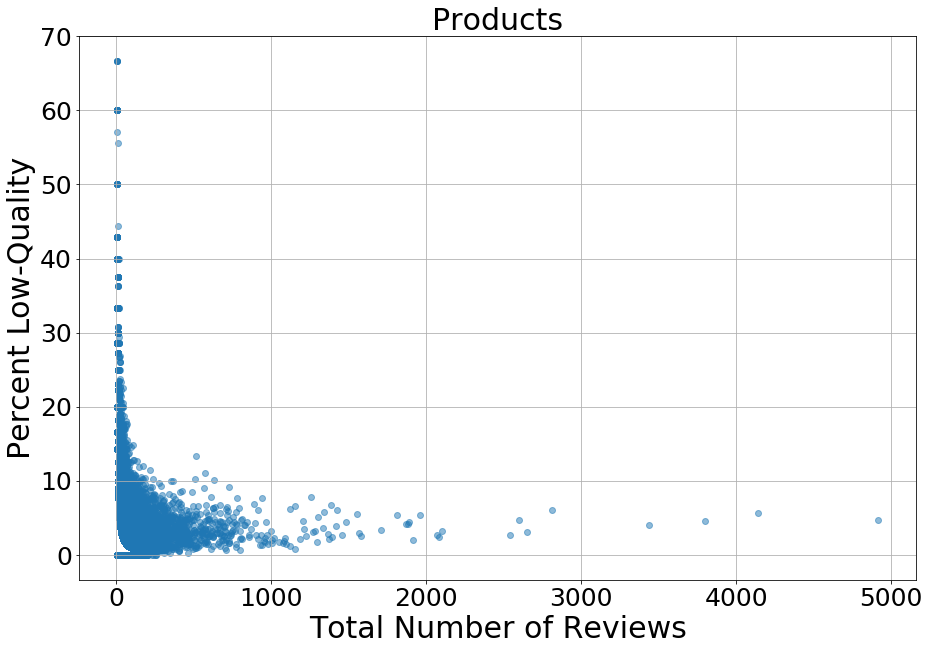
The peak is with four products that had 2/3 of their reviews being low-quality, each having a total of six reviews in the dataset: Serial ATA Cable, Kingston USB Flash Drive, AMD Processor, and a Netbook Sleeve.
For higher numbers of reviews, lower rates of low-quality reviews are seen. At first sight, this suggests that there may be a relationship between more reviews and better quality reviews that’s not necessarily due to popularity of the product. Popularity of a product would presumably bring in more low-quality reviewers just as it does high-quality reviewers. Perhaps products that more people review may be products that are easier to have things to say about. However, this does not appear to be the case. The top 5 review are the SanDisk MicroSDXC card, Chromecast Streaming Media Player, AmazonBasics HDMI cable, Mediabridge HDMI cable, and a Transcend SDHC card.
To check if there is a correlation between more low-quality reviews and fake reviews, I can use Fakespot.com. This is a website that uses reviews and reviewers from Amazon products that were known to have purchased fake reviews for their proprietary models to predict whether a new product has fake reviews. They rate the products by grade letter, saying that if 90% or more of the reviews are good quality it’s an A, 80% or more is a B, etc.
Here is the grade distribution for the products I found had 50% low-quality reviews or more (Blue; 28 products total), and the products with the most reviews in the UCSD dataset (Orange):
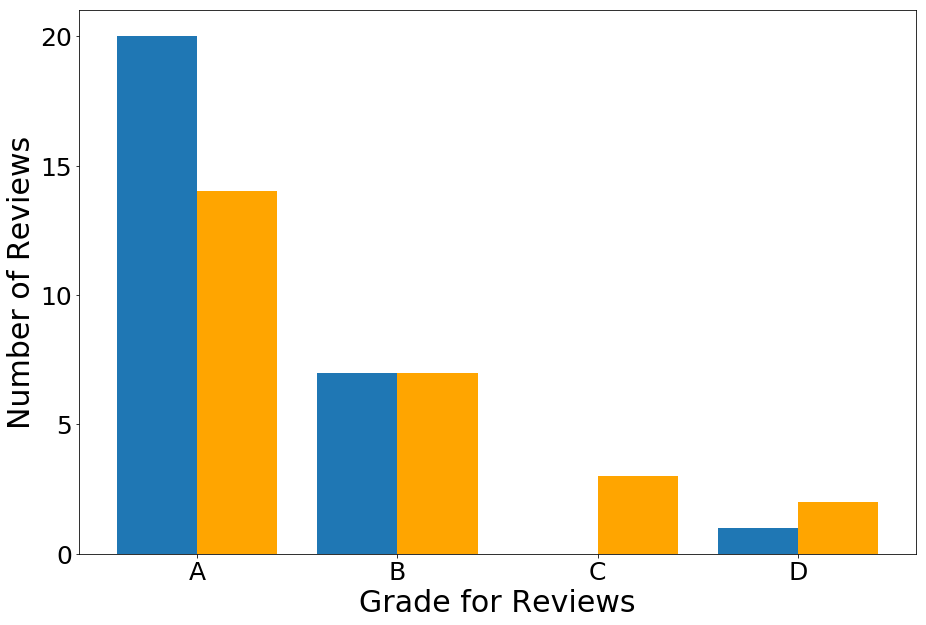
Note that the products with more low-quality reviews have higher grades more often, indicating that they would not act as a good tracer for companies who are potentially buying fake reviews.
Reviewers
Let’s take a deeper look at who is writing low-quality reviews. Here are the percent of low-quality reviews vs. the number of reviews a person has written.
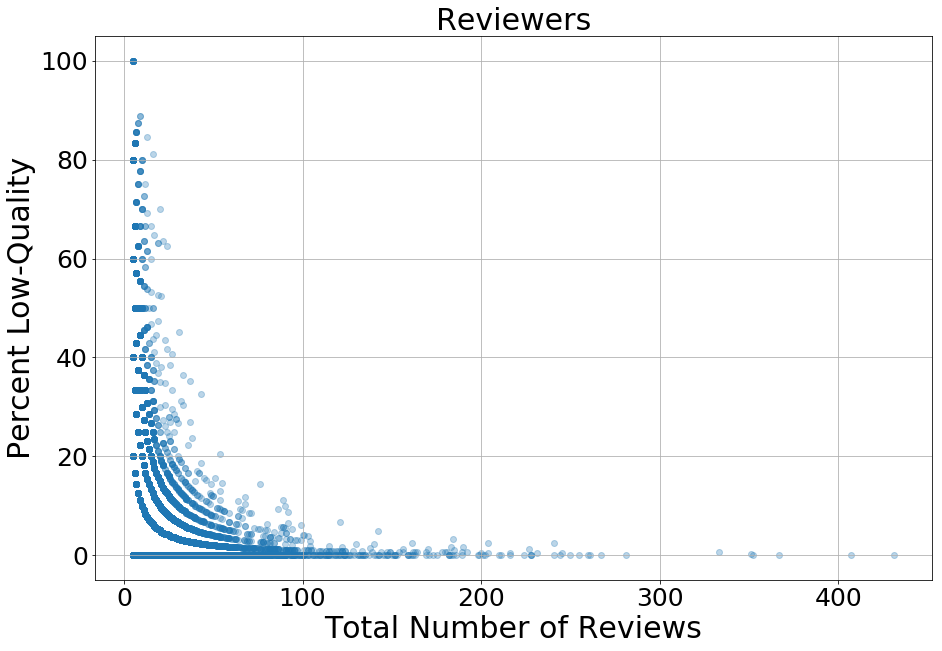
It can be seen that people who wrote more reviews had a lower rate of low-quality reviews (although, as shown below, this is not the rule). There are 13 reviewers that have 100% low-quality, all of which wrote a total of only 5 reviews.
There were some strange reviews that I found among these. For example, this reviewer wrote reviews for six cell phone covers on the same day. People don’t typically buy six different phone covers, so this is the only reviewer that I felt like had a real suspicion for being bought, although they were all verified purchases.
There is also an apparent word or length limit for new Amazon reviewers. To get past this, some will add extra random text. This reviewer wrote a five paragraph review using only dummy text. This type of thing is only seen in people’s earlier reviews while the length requirement is in effect. After that, they give minimal effort in their reviews, but they don’t attempt to lengthen them.
Next, in almost all of the low-quality reviewers, they wrote many reviews at a time. The likely reason people do so many reviews at once with no reviews for long periods of time is they simply don’t write them as they buy things. The list of products in their order history builds up, and they do all the reviews at once. As a good example, here’s a reviewer who was flagged as having 100% generic reviews. Note that the reviews are done in groupings by date, and while most of the reviews are either 4- or 5-stars, there is some variety. This isn’t suspicious, but rather illustrates that people write multiple reviews at a time.
But there are others who don’t write a unique review for each product. For example, some people would just write somthing like “good” for each review. This may be due to laziness, or simply that they have too many things to review that they don’t want to write unique reviews. As an extreme example found in one of the products that showed many low-quality reviews, here is a reviewer who used the phrase “on time and as advertised” in over 250 reviews. As you can see, he writes many uninformative 5-star reviews in a single day with the same phrase (the date is in the top left).
I spot checked many of these reviews, and did not see any that weren’t a verified purchase. A likely explanation is that this person wants to write reviews, but is not willing to put in the time necessary to properly review all of these purchases. While this is consistent with a vast majority of his reviews, not all the reviews are 5-stars and the lower-rated reviews are more informative. It is likely that he just copy/pastes the phrase for products he didn’t have a problem with, and then spends a little more time on the few products that didn’t turn out to be good.
This begs the question, what is the incentive to write all these reviews if no real effort is going to be given? If there is reward for giving positive reviews to purchases, then these would qualify as “fake” as they are directly or indirectly being paid for by the company. For example, there are reports of “Coupon Clubs” that tell members what to review what comments to downvote in exchange for Amazon coupons. But again, the reviews detected by this model were all verified purchases.
Summary
I found that instead of writing reviews as products are being purchased, many people appear to go through their purchase history and write many low-quality, quick reviews at the same time. Doing this benefits the star rating system in that otherwise reviews may be more filled only people who sit and make longer reviews or people who are dissatisfied, leaving out a count of people who are just satisfied and don’t have anything to say other than it works. Although these reviews do not add descriptive information about the products’ performance, these may simply indicate that people who purchased the product got what was expected, which is informative in itself.
This means that if a product has mostly high-star but low-quality and generic reviews, and/or the reviewers make many low-quality reviews at a time, this should not be taken as a sign that the reviews are fake and purchased by the company.